Image Captioning¶
Encoder Decoder Network¶
Last tutorial we introduced the encoder-decoder structure for translation. Rather than one model, we have two:
- Encoder that maps the input to some conceptual representation rather than individual words.
- Decoder that maps the representation into output words.

Image Encoder, Text Decoder¶
Since we have a separate encoder and decoder, we could also have an encoder that encodes images, and a decoder that decodes text, giving us an image captioning model.
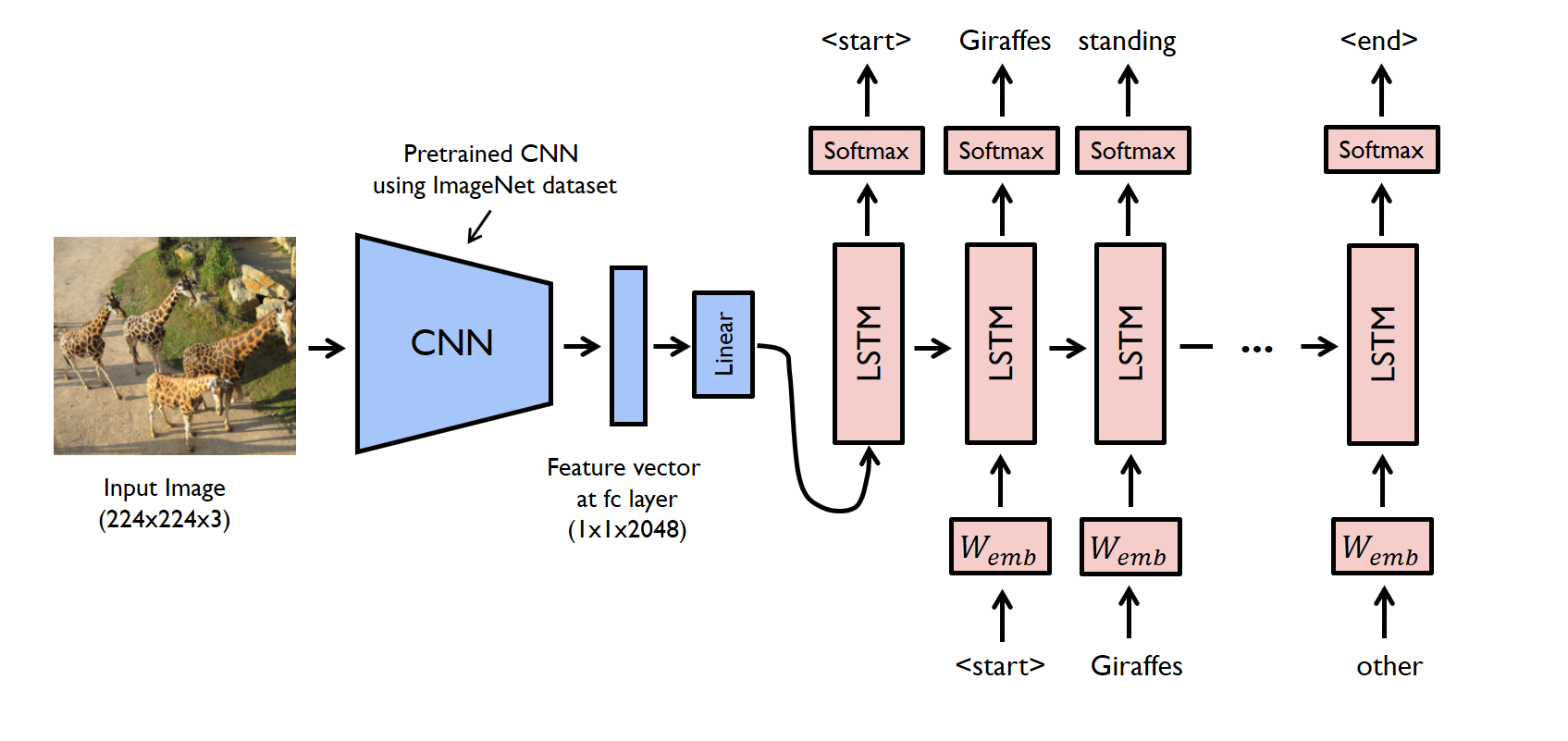
Encoder: Convolutional Neural Network¶
Wheras recurrent neural networks' repeating structure makes it a natural fit for sequential sentence data, convolutional neural networks are a natural fit for images.
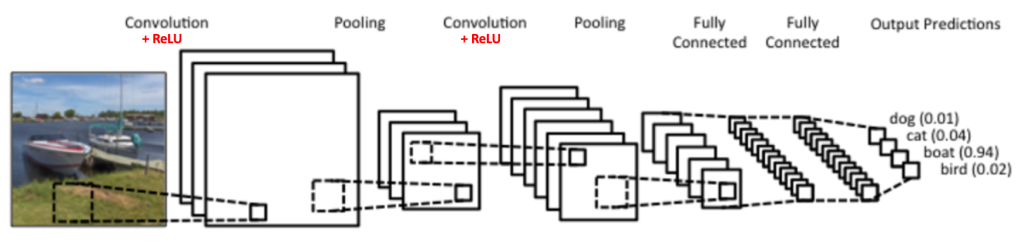
Convolutions look for visual traits in local patches in images, such as shapes and colors.

Exercise: Image Captioning¶
Today we'll implement an image captioning model to describe images.
Requirements¶
from collections import Counter, defaultdict
from gensim.models import Word2Vec
from IPython import display
from nltk import word_tokenize
from nltk.translate.bleu_score import sentence_bleu
from PIL import Image
from torch import nn
from torch.autograd import Variable
from torchvision import models, transforms
import json
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
import random
import torch
import torch.nn.functional as F
Here we will also define a constant to decide whether to use the GPU (with CUDA specifically) or the CPU. If you don't have a GPU, set this to False. Later when we create tensors, this variable will be used to decide whether we keep them on CPU or move them to GPU.
use_cuda = True
Loading Data¶
The dataset, MSCOCO, contains 5 English captions per image.
We will be representing each word in a language as a one-hot vector, or giant vector of zeros except for a single one (at the index of the word). Compared to the dozens of characters that might exist in a language, there are many many more words, so the encoding vector is much larger.
There's a bit of pre-processing code below, that loads the data and converts it into one-hot vectors.
# Load annotations file for the training images.
mscoco_train = json.load(open('data/annotations/train_captions.json'))
train_ids = [entry['id'] for entry in mscoco_train['images']][:1000]
train_id_to_file = {entry['id']: 'data/train2014/' + entry['file_name'] for entry in mscoco_train['images']}
# Extract out the captions for the training images
train_id_set = set(train_ids)
train_id_to_captions = defaultdict(list)
for entry in mscoco_train['annotations']:
if entry['image_id'] in train_id_set:
train_id_to_captions[entry['image_id']].append(entry['caption'])
# Load annotations file for the validation images.
mscoco_val = json.load(open('data/annotations/val_captions.json'))
val_ids = [entry['id'] for entry in mscoco_val['images']]
val_id_to_file = {entry['id']: 'data/val2014/' + entry['file_name'] for entry in mscoco_val['images']}
# Extract out the captions for the validation images
val_id_set = set(val_ids)
val_id_to_captions = defaultdict(list)
for entry in mscoco_val['annotations']:
if entry['image_id'] in val_id_set:
val_id_to_captions[entry['image_id']].append(entry['caption'])
# Load annotations file for the testing images
mscoco_test = json.load(open('data/annotations/test_captions.json'))
test_ids = [entry['id'] for entry in mscoco_test['images']]
test_id_to_file = {entry['id']: 'data/val2014/' + entry['file_name'] for entry in mscoco_test['images']}
sentences = [sentence for caption_set in train_id_to_captions.values() for sentence in caption_set]
# Lower-case the sentence, tokenize them and add <SOS> and <EOS> tokens
sentences = [["<SOS>"] + word_tokenize(sentence.lower()) + ["<EOS>"] for sentence in sentences]
# Create the vocabulary. Note that we add an <UNK> token to represent words not in our vocabulary.
vocabularySize = 1000
word_counts = Counter([word for sentence in sentences for word in sentence])
vocabulary = ["<UNK>"] + [e[0] for e in word_counts.most_common(vocabularySize-1)]
word2index = {word:index for index,word in enumerate(vocabulary)}
one_hot_embeddings = np.eye(vocabularySize)
# Define the max sequence length to be the longest sentence in the training data.
maxSequenceLength = max([len(sentence) for sentence in sentences])
def preprocess_numberize(sentence):
"""
Given a sentence, in the form of a string, this function will preprocess it
into list of numbers (denoting the index into the vocabulary).
"""
tokenized = word_tokenize(sentence.lower())
# Add the <SOS>/<EOS> tokens and numberize (all unknown words are represented as <UNK>).
tokenized = ["<SOS>"] + tokenized + ["<EOS>"]
numberized = [word2index.get(word, 0) for word in tokenized]
return numberized
def preprocess_one_hot(sentence):
"""
Given a sentence, in the form of a string, this function will preprocess it
into a numpy array of one-hot vectors.
"""
numberized = preprocess_numberize(sentence)
# Represent each word as it's one-hot embedding
one_hot_embedded = one_hot_embeddings[numberized]
return one_hot_embedded
# Define a global transformer to appropriately scale images and subsequently convert them to a Tensor.
img_size = 224
loader = transforms.Compose([
transforms.Resize(img_size),
transforms.CenterCrop(img_size),
transforms.ToTensor(),
])
def load_image(filename, volatile=False):
"""
Simple function to load and preprocess the image.
1. Open the image.
2. Scale/crop it and convert it to a float tensor.
3. Convert it to a variable (all inputs to PyTorch models must be variables).
4. Add another dimension to the start of the Tensor (b/c VGG expects a batch).
5. Move the variable onto the GPU.
"""
image = Image.open(filename).convert('RGB')
image_tensor = loader(image).float()
image_var = Variable(image_tensor, volatile=volatile).unsqueeze(0)
return image_var.cuda()
Exploring Data¶
We can explore the data a bit, to get a sense of what we're working with.
display.display(Image.open(train_id_to_file[train_ids[0]]))
for caption in train_id_to_captions[train_ids[0]]:
print(caption)

Image Encoder¶
We load in a pre-trained VGG-16 model and remove the final layer. This is similar to what we did when doing the hotdog/not-hotdog tutorial/competition.
vgg_model = models.vgg16(pretrained=True).cuda()
vgg_model.eval()
# Remove the final layer of the classifier, and indicate to PyTorch that the model is being used for inference
# rather than training (most importantly, this disables dropout).
modified_classifier = nn.Sequential(*list(vgg_model.classifier.children())[:-1])
modified_classifier.eval()
# Reassign the modified classifier back to the VGG model
vgg_model.classifier = modified_classifier
# Print out the model to see what it looks like now
vgg_model
Process Data¶
We now convert each image, into a vector representation, that serves as a semantic descriptor of the image. We do this by passing it through our modified VGG-16 model.
training_vectors = []
for i,image_id in enumerate(train_ids):
# Load/preprocess the image.
img = load_image(train_id_to_file[image_id])
# Run through the convolutional layers and resize the output.
output = vgg_model(img)
training_vectors.append(np.array(list(output.data.squeeze())))
# For simplicity, we convert this to a numpy array and save the result to a file.
training_vectors = np.stack(training_vectors, axis=0)
np.save(open('outputs/training_vectors', 'wb+'), training_vectors)
# Next we vectorize all of the validation images and write the results to a file.
validation_vectors = []
for image_id in val_ids:
# Load/preprocess the image.
img = load_image(val_id_to_file[image_id])
# Run through the convolutional layers and resize the output.
features_output = vgg_model.features(img)
classifier_input = features_output.view(1, -1)
# Run through all but final classifier layers.
output = modified_classifier(classifier_input)
validation_vectors.append(list(output.data.squeeze()))
# For simplicity, we convert this to a numpy array and save the result to a file.
validation_vectors = np.array(validation_vectors)
np.save(open('outputs/validation_vectors', 'wb+'), validation_vectors)
# Load in the vectors and print their sizes
training_vectors = np.load(open('outputs/training_vectors', 'rb'))
validation_vectors = np.load(open('outputs/validation_vectors', 'rb'))
print(training_vectors.shape)
print(validation_vectors.shape)
train_id_to_vector = {}
for i, train_id in enumerate(train_ids[:1000]):
train_id_to_vector[train_id] = training_vectors[i]
Image Captioning Model¶
Since we have a separate encoder and decoder, we could also have an encoder that encodes images, and a decoder that decodes text, giving us an image captioning model.
class ImageEncoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(ImageEncoder, self).__init__()
self.out = nn.Linear(input_size, hidden_size)
def forward(self, inputs):
return self.out(inputs)
class DecoderLSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(DecoderLSTM, self).__init__()
self.hidden_size = hidden_size
self.lstm = nn.LSTM(input_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
def forward(self, input, hidden):
output = F.relu(input)
output, hidden = self.lstm(output, hidden)
output = self.out(output)
output = F.log_softmax(output.squeeze())
return output.unsqueeze(0), hidden
encoder = ImageEncoder(input_size=4096, hidden_size=300).cuda()
decoder = DecoderLSTM(input_size=len(vocabulary), hidden_size=300, output_size=len(vocabulary)).cuda()
encoder
decoder
Training the Models¶
Defining the Loss Function¶
The next two functions are part of some other deep learning frameworks, but PyTorch has not yet implemented them. We can find some commonly-used open source worked arounds after searching around a bit: https://gist.github.com/jihunchoi/f1434a77df9db1bb337417854b398df1.
# The next two functions are part of some other deep learning frameworks, but PyTorch
# has not yet implemented them. We can find some commonly-used open source worked arounds
# after searching around a bit: https://gist.github.com/jihunchoi/f1434a77df9db1bb337417854b398df1.
def _sequence_mask(sequence_length, max_len=None):
if max_len is None:
max_len = sequence_length.data.max()
batch_size = sequence_length.size(0)
seq_range = torch.arange(0, max_len).long()
seq_range_expand = seq_range.unsqueeze(0).expand(batch_size, max_len)
seq_range_expand = Variable(seq_range_expand)
if sequence_length.is_cuda:
seq_range_expand = seq_range_expand.cuda()
seq_length_expand = (sequence_length.unsqueeze(1)
.expand_as(seq_range_expand))
return seq_range_expand < seq_length_expand
def compute_loss(logits, target, length):
"""
Args:
logits: A Variable containing a FloatTensor of size
(batch, max_len, num_classes) which contains the
unnormalized probability for each class.
target: A Variable containing a LongTensor of size
(batch, max_len) which contains the index of the true
class for each corresponding step.
length: A Variable containing a LongTensor of size (batch,)
which contains the length of each data in a batch.
Returns:
loss: An average loss value masked by the length.
"""
# logits_flat: (batch * max_len, num_classes)
logits_flat = logits.view(-1, logits.size(-1))
# log_probs_flat: (batch * max_len, num_classes)
log_probs_flat = logits_flat
# target_flat: (batch * max_len, 1)
target_flat = target.view(-1, 1)
# losses_flat: (batch * max_len, 1)
losses_flat = -torch.gather(log_probs_flat, dim=1, index=target_flat)
# losses: (batch, max_len)
losses = losses_flat.view(*target.size())
# mask: (batch, max_len)
mask = _sequence_mask(sequence_length=length, max_len=target.size(1))
losses = losses * mask.float()
loss = losses.sum() / length.float().sum()
return loss
Training Function¶
The function below trains the model. There's some interesting ideas in the function below, such as:
- Teacher forcing
- Masked loss
- Gradient Clipping
def train(input_variables,
embed_caption,
target_caption,
input_lens,
encoder,
decoder,
encoder_optimizer,
decoder_optimizer,
criterion,
embeddings=one_hot_embeddings):
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
# Pass the image through the encoder
encoder_output = encoder(input_variables).unsqueeze(0)
# Construct the decoder input (initially <SOS> for every batch)
decoder_input = Variable(torch.FloatTensor([[embeddings[word2index["<SOS>"]]
for i in range(embed_caption.size(1))]]))
decoder_input = decoder_input.cuda() if use_cuda else decoder_input
# Set the initial hidden state of the decoder to be the output of the encoder
decoder_hidden = (encoder_output, encoder_output)
# Prepare the results tensor
all_decoder_outputs = Variable(torch.zeros(*embed_caption.size()))
if use_cuda:
all_decoder_outputs = all_decoder_outputs.cuda()
all_decoder_outputs[0] = decoder_input
# Iterate over the indices after the first.
for t in range(1,embed_caption.size(0)):
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
if random.random() <= 0.8:
decoder_input = embed_caption[t].unsqueeze(0)
else:
topv, topi = decoder_output.data.topk(1)
#Prepare the inputs
decoder_input = torch.stack([Variable(torch.FloatTensor(embeddings[ni])).cuda()
for ni in topi.squeeze()]).unsqueeze(0)
# Save the decoder output
all_decoder_outputs[t] = decoder_output
loss = compute_loss(all_decoder_outputs.transpose(0,1).contiguous(),
target_caption.transpose(0,1).contiguous(),
Variable(torch.LongTensor(input_lens)).cuda())
loss.backward()
torch.nn.utils.clip_grad_norm(encoder.parameters(), 10.0)
torch.nn.utils.clip_grad_norm(decoder.parameters(), 10.0)
encoder_optimizer.step()
decoder_optimizer.step()
return loss.data[0]
Training the Model¶
Let's take a look at the first few images in the validation set, to get a sense of the captions that should be generated by our model.
display.display(Image.open(val_id_to_file[val_ids[0]]))
display.display(Image.open(val_id_to_file[val_ids[1]]))
display.display(Image.open(val_id_to_file[val_ids[2]]))



def pad_seq(arr, length, pad_token):
"""
Pad an array to a length with a token.
"""
if len(arr) == length:
return np.array(arr)
return np.concatenate((arr, [pad_token]*(length - len(arr))))
encoder_optimizer = torch.optim.Adam(decoder.parameters(), lr=0.01)
decoder_optimizer = torch.optim.Adam(decoder.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()
# Formulate the training data
train_data = [(train_id,caption) for train_id,captions in train_id_to_captions.items()
for caption in captions if len(caption) > 0]
random.shuffle(train_data)
num_epochs = 10
batch_size = 100
for _ in range(num_epochs):
for i in range(len(train_data)//batch_size):
# Get the data in the batch
batch = train_data[i*batch_size:(i+1)*batch_size]
# Get all of the image vectors
input_variable = np.stack([train_id_to_vector[train_id] for train_id,_ in batch])
input_variable = Variable(torch.FloatTensor(input_variable)).cuda()
# Get the sentences
sentences = [sentence for _,sentence in batch]
# Get the sentence lengths
sentence_lens = [len(preprocess_numberize(sentence)) for sentence in sentences]
# Determine length to pad everything to
max_len = max(sentence_lens)
# Preprocess all of the sentences in each batch
one_hot_embedded_list = [preprocess_one_hot(sentence) for sentence in sentences]
one_hot_embedded_list_padded = [pad_seq(embed, max_len, np.zeros(len(vocabulary)))
for embed in one_hot_embedded_list]
numberized_list = [preprocess_numberize(sentence) for sentence in sentences]
numberized_list_padded = [pad_seq(numb, max_len, 0).astype(torch.LongTensor) for numb in numberized_list]
# Convert to variables
embed_caption = Variable(torch.FloatTensor(one_hot_embedded_list_padded)).cuda()
target_caption = Variable(torch.LongTensor(numberized_list_padded)).cuda()
# Transpose from batch_size x max_seq_len x vocab_size to max_seq_len x batch_size x vocab_size
embed_caption = embed_caption.transpose(0, 1)
target_caption = target_caption.transpose(0, 1)
loss = train(input_variable,
embed_caption,
target_caption,
sentence_lens,
encoder,
decoder,
encoder_optimizer,
decoder_optimizer,
criterion)
if i % 10 == 0:
print(i,loss)
if i % 100 == 0:
print(caption_image(validation_vectors[0]))
print(caption_image(validation_vectors[1]))
print(caption_image(validation_vectors[2]))
Captioning!¶
Finally, we write a very simple method to run captioning for a given image vector.
def caption_image(image_vector, embeddings=one_hot_embeddings, max_length=20):
"""
Given an image vector, caption the image.
"""
# Pass the image through the encoder
input_variable = Variable(torch.FloatTensor([image_vector])).cuda()
encoder_output = encoder(input_variable).unsqueeze(0)
# Construct the decoder input (initially <SOS> for every batch)
decoder_input = Variable(torch.FloatTensor([[embeddings[word2index["<SOS>"]]]])).cuda()
# Set the initial hidden state of the decoder to be the output of the encoder
decoder_hidden = (encoder_output, encoder_output)
# Iterate over the indices after the first.
decoder_outputs = []
for t in range(1,max_length):
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
# Get the top result
topv, topi = decoder_output.data.topk(1)
ni = topi[0][0]
decoder_outputs.append(ni)
if vocabulary[ni] == "<EOS>":
break
#Prepare the inputs
decoder_input = Variable(torch.FloatTensor([[embeddings[ni]]])).cuda()
decoder_input = decoder_input.cuda() if use_cuda else decoder_input
return ' '.join(vocabulary[i] for i in decoder_outputs)
display.display(display.Image(val_id_to_file[val_ids[2]]))
caption_image(validation_vectors[2])
