Salary is incredibly important to all of us. In the most basic sense, the majority of people would not do their job if they were not paid for it.
But it's importance goes deeper than that. We often seek to make decisions that best optimize our future salary -- whether it be the cities we choose to live in or the majors we choose to study.
The first step to predicting salary is to do some preliminary exploration of our dataset.
It's interesting to note that the data seems to be a very specific slice of the population.
Every person in the dataset has at least a Bachelor's degree, with roughly 40% having a higher degree.
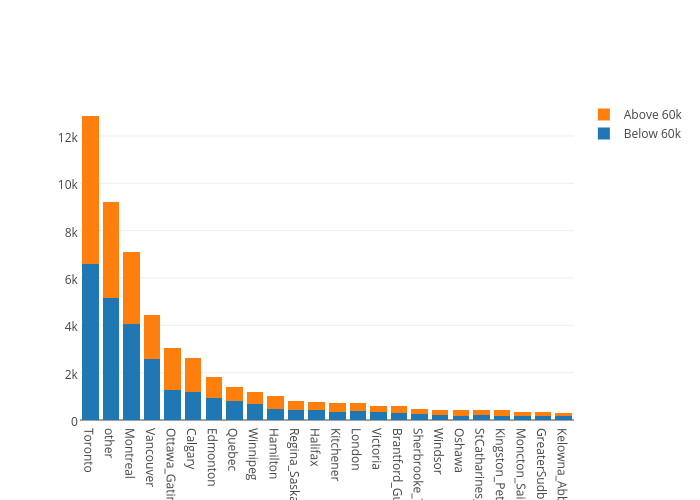
It's interesting to note the locations of people in the dataset. The plot below shows that the distribution is very much skewed to the major cities -- which questions whether analysis of this dataset is applicable outside the major cities.
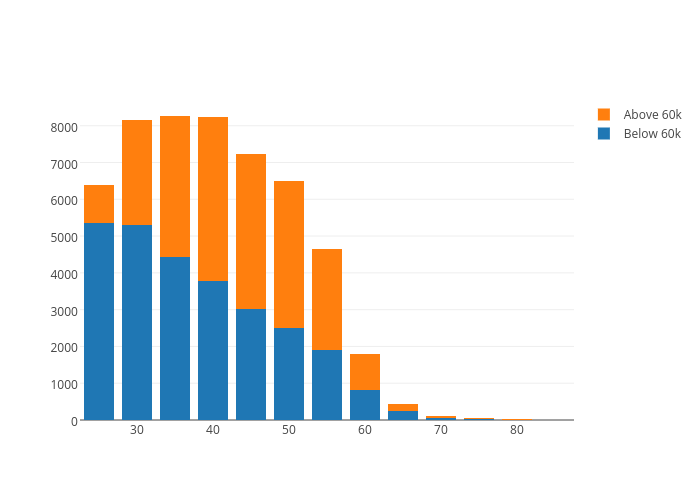
The plot below shows the distribution of ages. We see that it seems to be the case that as one ages -- there is a larger likelihood of making more than 60k.
It's also interesting to consider how the features interact with each other -- as well as with the class label (below/above 60k). The feature correlation matrix below answers that question. Note that you can click on the image to see it in an interactive view

There are some obvious correlations in the feature matrix (like between the different types of job labels and major labels) but there are some interesting ones as well.
It seems that there is a high correlation between the province and the location that a person studied -- which means that it's typical for people to work in the same province as they study.
Given some of the feature correlations, my intuition told me that some manual feature selection might help improve my model's accuracy -- however it did not seem to help.
I also attempted to add an additional feature which attempted to guess whether someone was working in their field of study -- however no change was observed in my model's accuracy.
I attempted numerous machine learning strategies -- such as model averaging, stacking and blending. The most succesful approach was to train a single Gradient Boosted Tree Classifier -- with parameters fine-tund with cross-validation.
I used One Hot Encoding for the categorical data, in order to remove any notion of ordinality, and automatic feature selection that removed all features lower than the median feature importance.
With 10-fold cross-validation, my model had an accuracy of 0.76570 (+/- 0.00243) and an Area Under Curve (using prediction probability) of 0.83931.
The resulting feature importances are shown below. The values represent how much a feature contributes to the resulting classification.

The most important feature is the number of hours worked in a week -- a fairly obvious feature choice. The second most important feature is the type of job one works in.
While one's job on it's own is definitely not enough to inform of us of their salary, it might be interesting to see the effect that it has.
Here, I select some random partition of the data. I keep all of the features constant except for the feature corresponding to the job one works in. I then observe how many people would be making above $60k out of the group of people for every single type of job.

It's interesting to note that a lot of the results are fairly uniform. This suggests that while one's job is an important factor -- it's not enough to change it without changing anything else (such as major or age).
Nonetheless we see some interesting information. If any random person moved to a technical field -- they'd have about a 40% larger chance of making above $60k. Public adminstration and the financial sector also tend to lead to higher salaries.
On the flipside, education tends to have significantly lower salaries.
This dataset is definitely not well distributed or large enough to draw any large general conclusions. However it seems to be the case that if you work long hours, are in a good field (hopefully a Technical field) -- you will most likely make a decent amount of money.
But hey, if you don't do any of these things, no need to worry -- my model only has 77% accuracy after all.